Bạn đã bao giờ yêu cầu AI giải một bài toán phức tạp và nhận về câu trả lời nghe có vẻ đúng nhưng thực ra sai logic chưa? Đó không phải vấn đề về kiến thức của model. Đó là vấn đề về cách AI xử lý bài toán khi không có đủ thời gian "dừng lại và nghĩ."
Khi Anthropic ra mắt Claude Extended Thinking vào tháng 2 năm 2025 cùng với Claude 3.7 Sonnet, họ không chỉ nâng cấp một model mới. Họ thay đổi cơ bản cách AI tiếp cận bài toán khó. Thay vì phải trả lời ngay lập tức, Claude được phép suy luận trong không gian nội tâm ẩn trước khi đưa ra câu trả lời cuối cùng.
Bài viết này giải thích Extended Thinking là gì, cơ chế hoạt động, và quan trọng nhất là khi nào bạn thực sự cần dùng nó trong dự án thực tế.
Key Takeaways - Claude Extended Thinking nâng điểm AIME 2024 từ 23.3% lên 80.0%, tăng hơn 3 lần so với chế độ thường (Anthropic, 2025) - Token budget tối thiểu 1,024 tokens; nên bắt đầu thấp rồi tăng dần vì accuracy tăng theo quy luật logarithmic - Phù hợp nhất cho toán học, lập trình phức tạp, phân tích sâu nhiều bước; không hiệu quả cho câu hỏi đơn giản - Thinking tokens bị tính phí theo output token rate dù dùng summarized hay omitted display
Claude Extended Thinking Là Gì và Tại Sao Nó Khác Với AI Thông Thường?
Claude Extended Thinking nâng điểm GPQA Diamond (bộ câu hỏi tiến sĩ về khoa học) từ 68.0% lên 84.8%, một bước nhảy 16.8 điểm phần trăm so với chế độ thông thường (Anthropic, 2025). Con số này không tự nhiên xuất hiện. Nó đến từ một thay đổi kiến trúc cơ bản: thêm không gian làm việc ẩn gọi là thinking tokens.
Trong chế độ thông thường, Claude nhận input và tạo output theo một luồng tuyến tính. Giống như bạn phải trả lời ngay không có thời gian suy nghĩ. Extended Thinking thêm một giai đoạn trung gian nơi model có thể:
- Chia nhỏ bài toán thành các bước nhỏ hơn
- Thử nhiều hướng tiếp cận rồi quay lại khi gặp ngõ cụt
- Kiểm tra tính nhất quán của từng bước lập luận
- Tinh chỉnh câu trả lời trước khi gửi ra ngoài
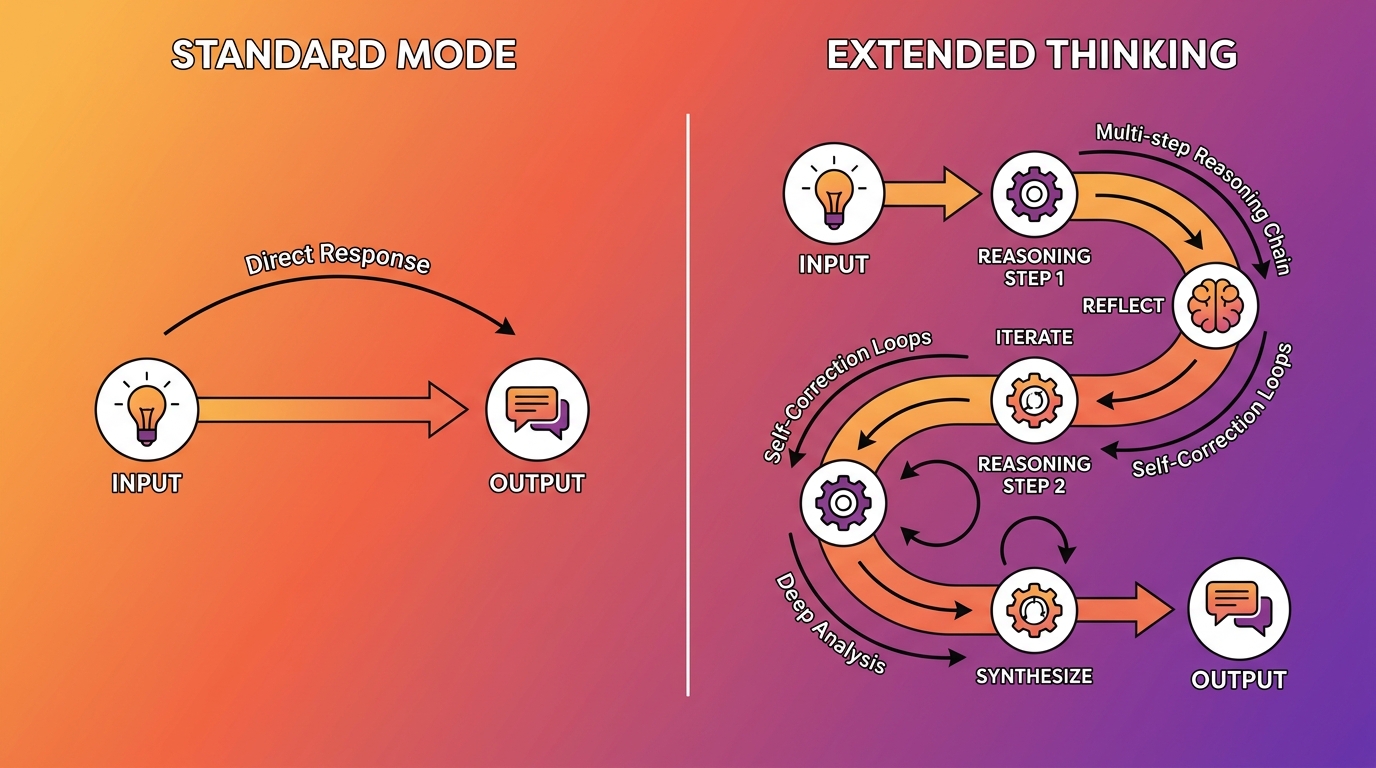
Thinking tokens này không xuất hiện trực tiếp trong phần output mà người dùng thấy. Tuy nhiên, chúng có mặt trong API response dưới dạng một block riêng biệt với type: "thinking", cho phép developer theo dõi quá trình suy luận khi cần debug.
Điểm ít được nhắc đến là Extended Thinking không đơn giản là "bổ sung bước suy luận" vào một model sẵn có. Anthropic huấn luyện Claude 3.7 Sonnet từ đầu với khả năng này như một phần của kiến trúc, không phải thêm vào từ bên ngoài sau khi training. Đây là lý do không phải model nào cũng hỗ trợ tính năng này, và kết quả chỉ tốt khi dùng đúng model được xây dựng có chủ đích cho Extended Thinking.
Để có cái nhìn tổng quan về toàn bộ hệ sinh thái Claude, xem [INTERNAL-LINK: hướng dẫn đầy đủ về Claude AI cho developer → pillar page /claude].
Thinking Tokens Hoạt Động Như Thế Nào? Giải Mã Token Budget
Claude 3.7 Sonnet với Extended Thinking đạt 96.2% trên MATH 500 benchmark (WandB Evaluation, 2025). Nhưng hiệu quả đó phụ thuộc trực tiếp vào tham số budget_tokens. Đây là số token tối đa Claude được phép dùng cho quá trình suy nghĩ nội tâm trước khi tạo ra output.
Các ngưỡng quan trọng cần nhớ:
- Tối thiểu bắt buộc: 1,024 tokens
- Tối đa: phụ thuộc context window của model, nhưng
budget_tokensphải nhỏ hơnmax_tokens - Claude 3.7 Sonnet hỗ trợ output lên đến 64,000 tokens khi bật Extended Thinking, gấp 8 lần giới hạn thông thường
Quy luật logarithmic quan trọng nhất: Nghiên cứu của Anthropic xác nhận accuracy tăng theo logarithm của số thinking tokens. Điều này có nghĩa là 4,000 tokens đầu tiên mang lại cải thiện lớn nhất. Từ 32,000 tokens trở lên, mỗi token thêm vào mang lại ít giá trị hơn đáng kể. Bắt đầu thấp, đo kết quả thực tế, rồi mới tăng lên là chiến lược đúng.
WandB ghi nhận trong thực tế kiểm thử với bộ câu hỏi AIME: chuyển từ 0 tokens (chế độ thường, đạt 20.0%) lên 16,000-24,000 thinking tokens nâng tỷ lệ đúng lên 50.0%, gần như gấp đôi rưỡi hiệu quả (WandB, 2025). Điểm thú vị là nhảy từ 16,000 lên 24,000 tokens không mang lại thêm cải thiện, khẳng định quy luật logarithmic.
Một điểm ít người để ý: Claude không nhất thiết sử dụng hết budget. Khi bài toán không đủ phức tạp, model tự dừng sớm và không lãng phí token. Budget là giới hạn trên, không phải ràng buộc bắt buộc phải tiêu hết.
Xem thêm [INTERNAL-LINK: so sánh Claude 3.7 Sonnet với các reasoning model khác (o3-mini, DeepSeek R1) → sibling article trong cluster BA].
Hiệu Suất Thực Tế: Extended Thinking Cải Thiện Độ Chính Xác Bao Nhiêu?
Trên AIME 2024, Claude 3.7 Sonnet với Extended Thinking đạt 80.0% so với 23.3% của chế độ thường (Anthropic, 2025). Con số 56.7 điểm phần trăm chênh lệch đặt Extended Thinking ngang hàng với o3-mini (83.3%) trên cùng bài kiểm tra, dù Claude không phải là model được xây dựng chuyên biệt cho toán học.
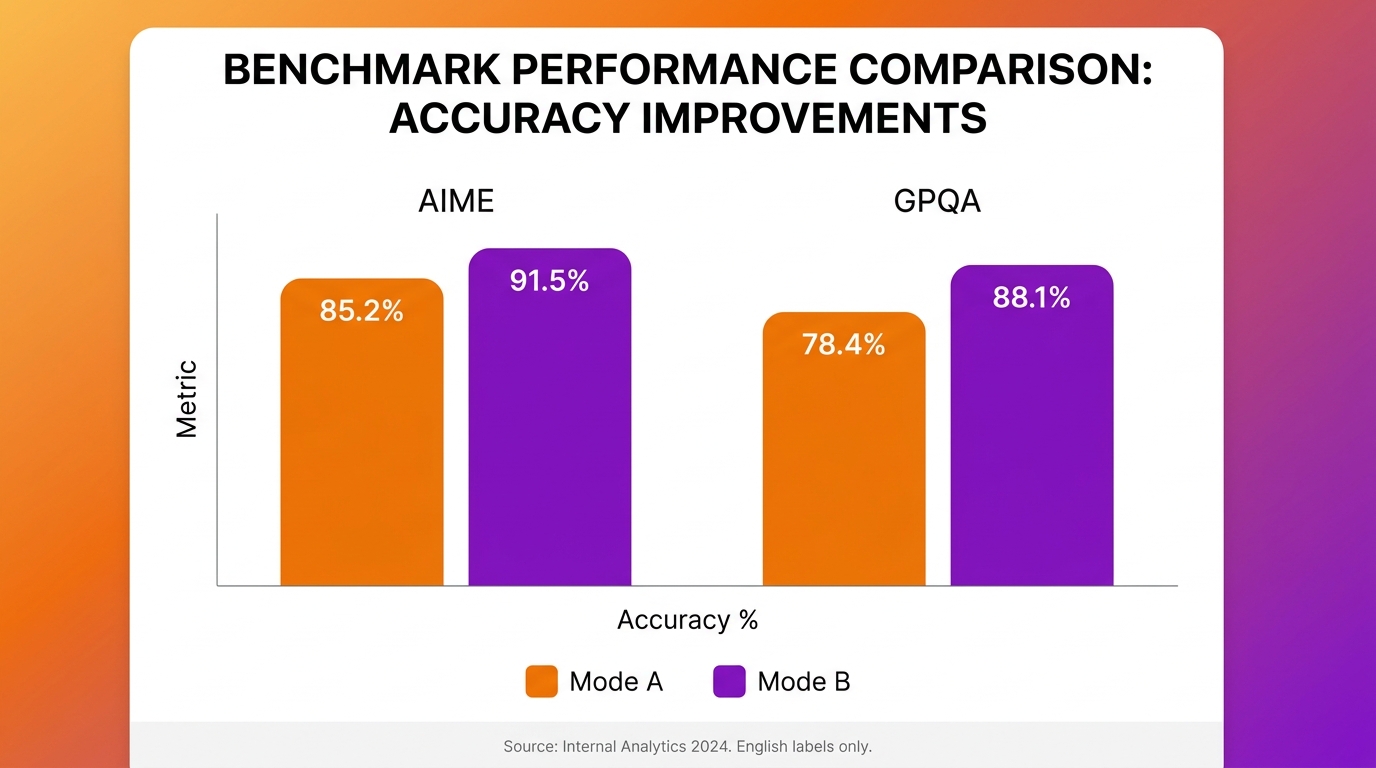
So sánh trên nhiều benchmark:
| Benchmark | Chế độ thường | Extended Thinking | Tăng |
|---|---|---|---|
| AIME 2024 (toán thi đấu) | 23.3% | 80.0% | +56.7 pp |
| GPQA Diamond (khoa học tiến sĩ) | 68.0% | 84.8% | +16.8 pp |
| MATH 500 | N/A | 96.2% | N/A |
| IFEval (instruction following) | 90.8% | 93.2% | +2.4 pp |
| SWE-bench Verified (lập trình) | 62.3% | 70.3%* | +8.0 pp |
*Với custom scaffold
Mức độ cải thiện không đồng đều giữa các loại task. Toán học và khoa học tự nhiên hưởng lợi nhiều nhất vì đòi hỏi nhiều bước kiểm tra tính đúng đắn. Instruction-following chỉ tăng nhẹ vì bản thân task không cần reasoning sâu.
Điều này gợi ý một nguyên tắc thực tế: Extended Thinking tạo ra giá trị khi "đường đi" từ câu hỏi đến câu trả lời có nhiều bước trung gian và mỗi bước có thể sai. Với task chỉ cần truy xuất thông tin trực tiếp, thinking tokens không mang lại nhiều giá trị bổ sung.
Trong bối cảnh agentic workflows, con số còn ấn tượng hơn: think tool trên τ-bench airline domain tăng hiệu suất 54% tương đối, từ 0.370 lên 0.570 (Anthropic Engineering, 2025). Với các ứng dụng agent phức tạp có nhiều tool calls, đây là cải thiện đáng đầu tư.
Cách Tích Hợp Extended Thinking Vào API: Hướng Dẫn Thực Hành
Khi Extended Thinking được bật trên Claude 3.7 Sonnet, output capacity tăng lên 64,000 tokens so với 8,192 tokens thông thường (Anthropic Docs, 2025). Đây là thay đổi cần nhớ ngay khi thiết kế pipeline vì nó ảnh hưởng trực tiếp đến cách bạn đặt max_tokens.
Cấu hình API cơ bản chỉ cần thêm một object thinking vào request:
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-3-7-sonnet-20250219",
max_tokens=16000,
thinking={
"type": "enabled",
"budget_tokens": 8000 # bat dau thap, do ket qua roi tang
},
messages=[{
"role": "user",
"content": "Giai phuong trinh: x^3 - 6x^2 + 11x - 6 = 0. Cho tung buoc tinh."
}]
)
for block in response.content:
if block.type == "thinking":
print(f"[Qua trinh suy luan]: {block.thinking[:200]}...")
elif block.type == "text":
print(f"[Ket qua]: {block.text}")
Hai constraint quan trọng nhất khi dùng tool use:
Khi bật thinking, chỉ có thể dùng tool_choice: {"type": "auto"} hoặc {"type": "none"}. Không thể dùng tool_choice: {"type": "any"} hay chỉ định tool cụ thể. Đây là giới hạn hiện tại của API, cần điều chỉnh nếu code cũ của bạn dùng forced tool selection.
Multi-turn conversation: Thinking blocks phải được giữ nguyên và truyền lại vào message history ở các lượt tiếp theo. Không được modify hay bỏ qua chúng. API kiểm tra signature field của thinking block để đảm bảo tính nhất quán qua các lượt hội thoại.
Interleaved Thinking cho agentic workflows: Thêm beta header interleaved-thinking-2025-05-14 để Claude có thể suy nghĩ giữa các tool calls. Tính năng này đặc biệt hữu ích khi pipeline có nhiều bước tool use liên tiếp và mỗi bước cần phân tích kết quả từ bước trước.
Prompt caching với Extended Thinking: System prompt với cache_control vẫn hoạt động bình thường. Tuy nhiên, thay đổi budget_tokens sẽ invalidate message history cache. Nếu chạy Extended Thinking session dài, đặt cache TTL là 1 giờ thay vì 5 phút mặc định để tránh cache miss không cần thiết.
Tham khảo [INTERNAL-LINK: toi uu prompt caching va cost trong Anthropic API → sibling article trong cluster BA] để biết cách kết hợp caching với Extended Thinking nhằm giảm chi phí tổng thể.
Khi Nào Nên Dùng Extended Thinking? Trường Hợp Phù Hợp và Không Phù Hợp
Anthropic chiếm 40% enterprise LLM spending vào năm 2025, tăng từ 24% năm 2024 (Menlo Ventures, 2025). Một phần của tăng trưởng này đến từ developer biết chính xác khi nào cần dùng Extended Thinking và khi nào standard mode là đủ.
Nên dùng Extended Thinking khi:
- Toán và khoa học tự nhiên: Bài toán nhiều bước, đòi hỏi kiểm tra tính đúng đắn từng bước
- Competitive programming: LeetCode Hard, thuật toán phức tạp, tối ưu hóa có nhiều ràng buộc
- Phân tích văn bản phức tạp: Đánh giá hợp đồng pháp lý, phân tích tài chính nhiều biến số
- Research synthesis: Tổng hợp thông tin từ nhiều nguồn mâu thuẫn nhau
- Agentic tasks: Multi-step workflow với tool use phức tạp, cần suy nghĩ giữa các bước
Không nên dùng khi:
- Câu hỏi factual đơn giản (tra cứu thông tin thẳng)
- Summarization văn bản ngắn
- Translation hoặc rewriting cơ bản
- Chatbot cần response time dưới 2 giây
- Ứng dụng volume cao với budget eo hẹp
Trong thực tế làm việc với các use case kỹ thuật về system design, Extended Thinking với budget 8,000 tokens cho câu trả lời đầy đủ hơn và ít mắc lỗi logic hơn so với chế độ thường. Tuy nhiên, với câu hỏi dạng "định nghĩa X là gì" hay "liệt kê các tính năng của Y," không có sự khác biệt đáng kể đủ để biện minh cho chi phí cao hơn.
Câu hỏi thực tế để tự kiểm tra: "Bài toán này có nhiều hơn 3 bước logic không, và mỗi bước có thể dẫn đến sai lầm không?" Nếu có, Extended Thinking có giá trị. Nếu không, standard mode là đủ.
Xem thêm [INTERNAL-LINK: so sanh Claude API voi OpenAI API cho developer Viet Nam → cross Hub A article ve AI tools] để cân nhắc lựa chọn phù hợp với từng use case.
Chi Phí và Tối Ưu Token Budget: Làm Thế Nào Để Dùng Hiệu Quả?
Thinking tokens được tính phí theo output token rate, và bạn bị tính phí cho toàn bộ tokens tạo ra bên trong, kể cả khi dùng display: "summarized" hay "omitted" (Anthropic Docs, 2025). Đây là điểm khiến nhiều developer bất ngờ lần đầu dùng vì bill thực tế cao hơn họ ước tính từ API response.
4 chiến lược tối ưu chi phí thực tế:
1. Bắt đầu thấp, đo accuracy, rồi tăng dần
Đừng set 32,000 tokens từ đầu. Thử 4,000 tokens, đánh giá kết quả trên bộ test case đại diện, rồi tăng lên 8,000 nếu cần. Nhớ quy luật logarithmic: phần lớn value đến từ tokens đầu tiên.
2. Tách use case theo yêu cầu độ chính xác
Dùng standard mode cho phần lớn requests thông thường. Chỉ kích hoạt Extended Thinking khi phát hiện bài toán phức tạp, ví dụ dựa trên keyword classifier hoặc routing logic riêng trong pipeline.
3. Cache system prompt để giảm chi phí input
Với session Extended Thinking dài, system prompt thường chiếm nhiều tokens. Cache nó với TTL 1 giờ. Đây là cách giảm chi phí không ảnh hưởng đến chất lượng output.
4. Summarized display không giảm chi phí, chỉ giảm bandwidth
display: "summarized" thu gọn phần thinking trong API response để tiết kiệm network bandwidth, nhưng không giảm số thinking tokens được tính phí. Dùng nó khi không cần xem quá trình suy luận, không phải để giảm chi phí.
Theo [INTERNAL-LINK: chien luoc quan ly chi phi Claude API khi scale → Hub B article ve cost optimization Claude], 50% developer hiện dùng AI coding tools hàng ngày, và các team báo cáo tăng velocity hơn 15% (Menlo Ventures, 2025), nhưng ROI chỉ thực sự tốt khi chi phí AI được kiểm soát có chiến lược.
Sẵn sàng thử Extended Thinking trong dự án?
Đọc thêm [INTERNAL-LINK: Claude 3.7 Sonnet trong production — use cases va case studies thuc te → sibling article trong cluster BA] để xem cách các engineering team thực tế đang tích hợp Extended Thinking vào sản phẩm, từ math tutoring apps đến legal document analysis.
Câu Hỏi Thường Gặp Về Claude Extended Thinking
Extended Thinking có khác với chain-of-thought prompting không?
Có, khác biệt cơ bản. Chain-of-thought prompting yêu cầu model tạo ra reasoning steps trong output hiển thị với người dùng. Extended Thinking là cơ chế cấp độ model: thinking tokens được tạo ra bên trong không gian ẩn, không cần yêu cầu trong prompt, và không nhất thiết xuất hiện trong output cuối. Kết quả thực nghiệm cho thấy Extended Thinking nâng điểm AIME từ 23.3% lên 80.0% (Anthropic, 2025), vượt xa hiệu quả thông thường của chain-of-thought prompting.
Token budget tối thiểu và tối đa là bao nhiêu?
Budget tối thiểu là 1,024 tokens theo API spec và không thể đặt thấp hơn. Budget tối đa phụ thuộc vào context window của model và phải nhỏ hơn max_tokens được đặt trong request. Anthropic khuyến nghị bắt đầu từ mức tối thiểu, tăng dần khi cần. Trên thực tế, hầu hết use case không cần vượt 32,000 tokens vì accuracy tăng logarithmically và diminishing returns rõ rệt ở mức cao.
Thinking tokens có tốn kém hơn không?
Có, đáng kể. Thinking tokens được tính theo output token rate. Và bạn bị tính phí cho toàn bộ thinking tokens được tạo ra bên trong, không phải chỉ phần hiển thị. Dùng display: "summarized" hay "omitted" không giảm chi phí, chỉ giảm data transfer. Nên dùng Extended Thinking chọn lọc cho task cần accuracy cao, không phải mọi request.
Model nào hỗ trợ Extended Thinking?
Tính đến giữa năm 2026, Extended Thinking với manual budget_tokens hỗ trợ trên Claude 3.7 Sonnet và Claude Haiku 4.5 (model Haiku đầu tiên có tính năng này). Các model Claude 4 series như Opus 4.6 và Sonnet 4.6 dùng adaptive thinking thay vì manual budget, được Anthropic khuyến nghị hơn. Claude 3.5 Haiku không hỗ trợ Extended Thinking. Luôn kiểm tra tài liệu chính thức của Anthropic để cập nhật mới nhất.
Streaming có hoạt động với Extended Thinking không?
Có, API hỗ trợ full streaming với Extended Thinking. Khi dùng display: "summarized", bạn nhận thinking_delta events cho phần suy luận và text_delta events cho output. Khi dùng display: "omitted" (mặc định trên Opus 4.7+), chỉ có signature_delta cho thinking block, giảm streaming overhead. Response text vẫn stream bình thường sau khi quá trình suy nghĩ hoàn tất.
Kết Luận
Claude Extended Thinking đại diện cho bước tiến thực sự trong khả năng reasoning của AI, nhưng chỉ khi áp dụng đúng loại bài toán. Với các task đòi hỏi multi-step reasoning như toán học, competitive coding, hay phân tích phức tạp nhiều biến số, mức cải thiện lên đến 56.7 điểm phần trăm là quá đáng kể để bỏ qua.
Điểm mấu chốt khi bắt đầu làm việc với Extended Thinking:
- Bắt đầu với budget 1,024 đến 4,000 tokens, đo kết quả thực tế trước khi tăng
- Chỉ dùng cho task thực sự cần accuracy cao, không phải mọi request
- Tính phí dựa trên thinking tokens thực tế tạo ra bên trong, không phải budget đặt ra
- Multi-turn conversations cần giữ nguyên thinking blocks trong message history
Extended Thinking không phải là giải pháp vạn năng. Nó là một công cụ chuyên biệt với chi phí cao hơn và latency cao hơn. Dùng nó có chủ đích, và nó sẽ mang lại giá trị thực sự cho những bài toán xứng đáng.
Khám phá thêm về hệ sinh thái Claude và các tính năng developer tại [INTERNAL-LINK: trung tam huong dan Claude cho developer Viet Nam → pillar /claude] để xây dựng ứng dụng AI hiệu quả hơn.
Nguồn tham khảo chính: Anthropic Extended Thinking Docs | Claude 3.7 Sonnet Release | Anthropic Engineering Blog - Think Tool | Menlo Ventures State of GenAI 2025 | WandB Claude 3.7 Evaluation