Trong năm 2024, doanh nghiệp toàn cầu mất $67.4 tỷ đô la vì AI hallucination theo khảo sát Responsible AI của EY (2025). Và đây là phần đáng lo ngại: nhiều tổ chức nghĩ rằng họ đã giải quyết vấn đề này khi triển khai RAG.
Thực tế không đơn giản như vậy. RAG (Retrieval-Augmented Generation) giúp giảm hallucination đáng kể, nhưng không loại bỏ hoàn toàn. Khi pipeline không được thiết kế kỹ, hệ thống RAG vẫn có thể bịa đặt thông tin ở tới 40% phản hồi. Bài này sẽ cho bạn biết hallucination xảy ra ở đâu trong RAG pipeline, cách đo lường chính xác bằng RAGAS metrics, và năm lớp phòng thủ cụ thể cần triển khai trước khi đưa hệ thống vào production.
Nếu bạn chưa quen với khái niệm nền tảng, hãy xem trước bài RAG là gì và hoạt động ra sao trong hệ thống doanh nghiệp trước khi đọc tiếp.
Key Takeaways - RAG giảm hallucination lên đến 71%, nhưng chỉ khi retrieval quality và context grounding được tối ưu đúng (Blockchain Council, 2025). - RAGAS faithfulness score dưới 0.8 là dấu hiệu rõ LLM đang hallucinate; cần review pipeline ngay. - 47% enterprise AI users đã ra quyết định quan trọng dựa trên nội dung hallucinated, cho thấy đây là rủi ro kinh doanh thực sự, không chỉ là vấn đề kỹ thuật (EY, 2025).
RAG Hallucination Là Gì Và Tại Sao Nó Vẫn Xảy Ra Ngay Cả Khi Dùng RAG?
Dù có RAG, khoảng 18% tương tác của enterprise chatbot trong môi trường live vẫn chứa hallucination (SQMagazine, 2026). Vấn đề không nằm ở mô hình, mà ở cách pipeline xử lý thông tin trước khi mô hình tiếp nhận câu hỏi.
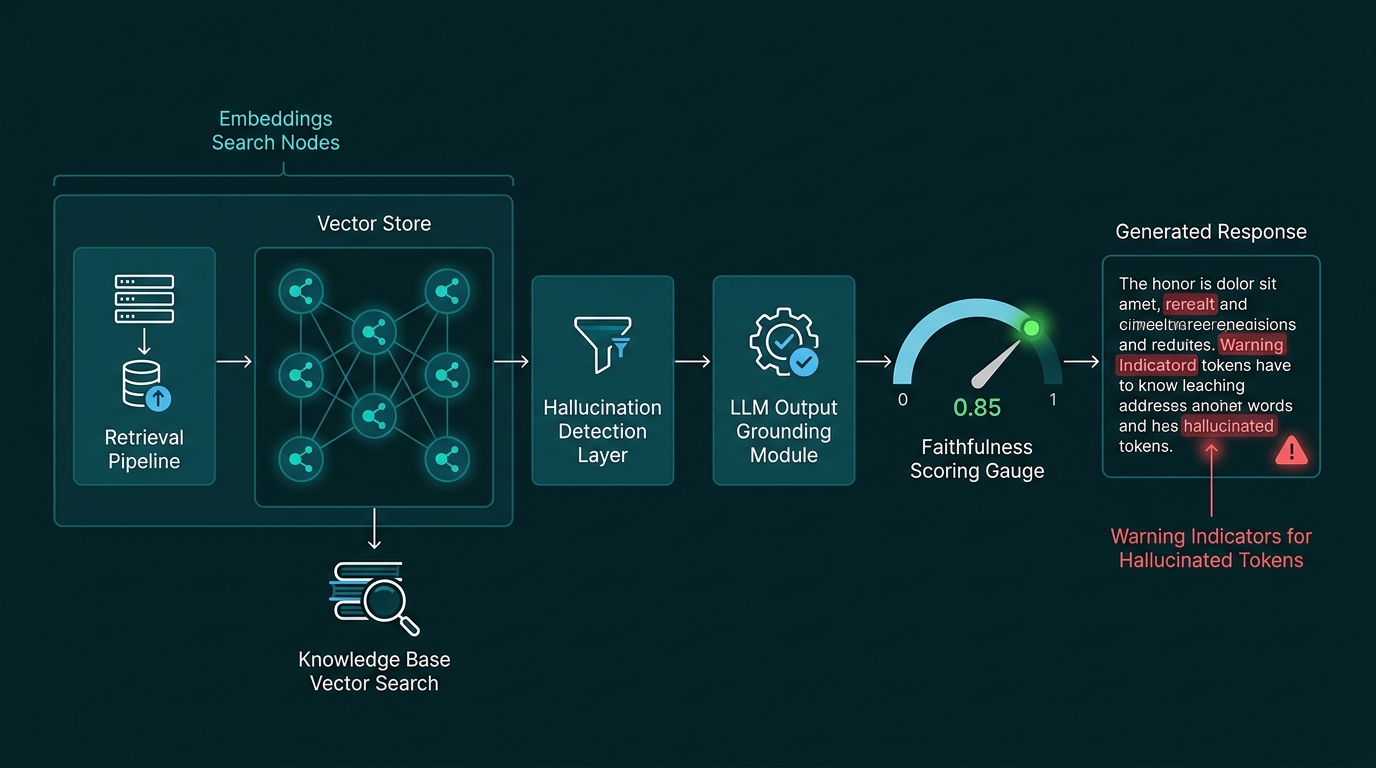
Có hai loại RAG hallucination chính mà đội kỹ thuật cần phân biệt rõ:
Intrinsic hallucination xảy ra khi mô hình tạo ra thông tin mâu thuẫn hoặc không có trong context được cung cấp. Ví dụ: context nói "sản phẩm có giá 500,000 VND" nhưng mô hình trả lời "450,000 VND" vì nó ưu tiên kiến thức tham số cũ hơn.
Extrinsic hallucination xảy ra khi mô hình bóp méo hoặc suy diễn sai từ context có sẵn. Đây là loại tinh vi hơn. Mô hình thực sự đã đọc tài liệu nhưng tổng hợp sai nghĩa, bỏ sót điều kiện quan trọng, hoặc áp dụng thông tin từ đoạn văn này sang ngữ cảnh của đoạn văn khác.
Trong thực tế, phần lớn RAG hallucination không phải do mô hình tự bịa đặt. Chúng xảy ra vì pipeline mang đến cho mô hình những đoạn context sai, thiếu, hoặc mâu thuẫn nhau. Khi retriever lấy về 5 chunks có nội dung xung đột, mô hình không có cách nào biết phần nào đúng. Nó sẽ tổng hợp tất cả lại và kết quả thường là thông tin sai.
Ba điểm thất bại phổ biến nhất trong production RAG:
- Retrieval sai: vector search lấy về các đoạn văn liên quan về mặt ngữ nghĩa nhưng không phải câu trả lời thực sự cần thiết.
- Chunking kém: các đoạn văn bị cắt lìa mất ngữ cảnh, khiến mô hình thiếu thông tin để trả lời chính xác.
- Context quá tải: khi context window chứa quá nhiều thông tin ít liên quan, mô hình bị phân tâm và dễ sinh ra nội dung không chính xác.
Theo nghiên cứu của ReDeEP (OpenReview, 2025), hallucination xảy ra khi Knowledge FFNs trong LLM đặt quá nhiều trọng số vào kiến thức tham số của chính nó, thay vì giữ nguyên thông tin từ context được cung cấp.
Theo k2view RAG Hallucination Guide (2025, k2view.com), RAG được triển khai tốt giảm tỷ lệ hallucination từ mức 20-40% của standalone LLM xuống dưới 5% trong enterprise deployment. Nhưng "triển khai tốt" có nghĩa là toàn bộ pipeline từ chunking đến evaluation đều phải được kiểm soát chặt chẽ, không chỉ là thêm một retriever vào trước LLM.
Làm Thế Nào Để Đo RAG Hallucination Chính Xác Trong Production?
Trong năm 2025, RAGAS đã trở thành framework chuẩn để đo hallucination trong production. Theo RAGAS documentation, faithfulness score trên 0.8 kết hợp với context precision trên 0.8 cho thấy retrieval quality đã sẵn sàng cho production.
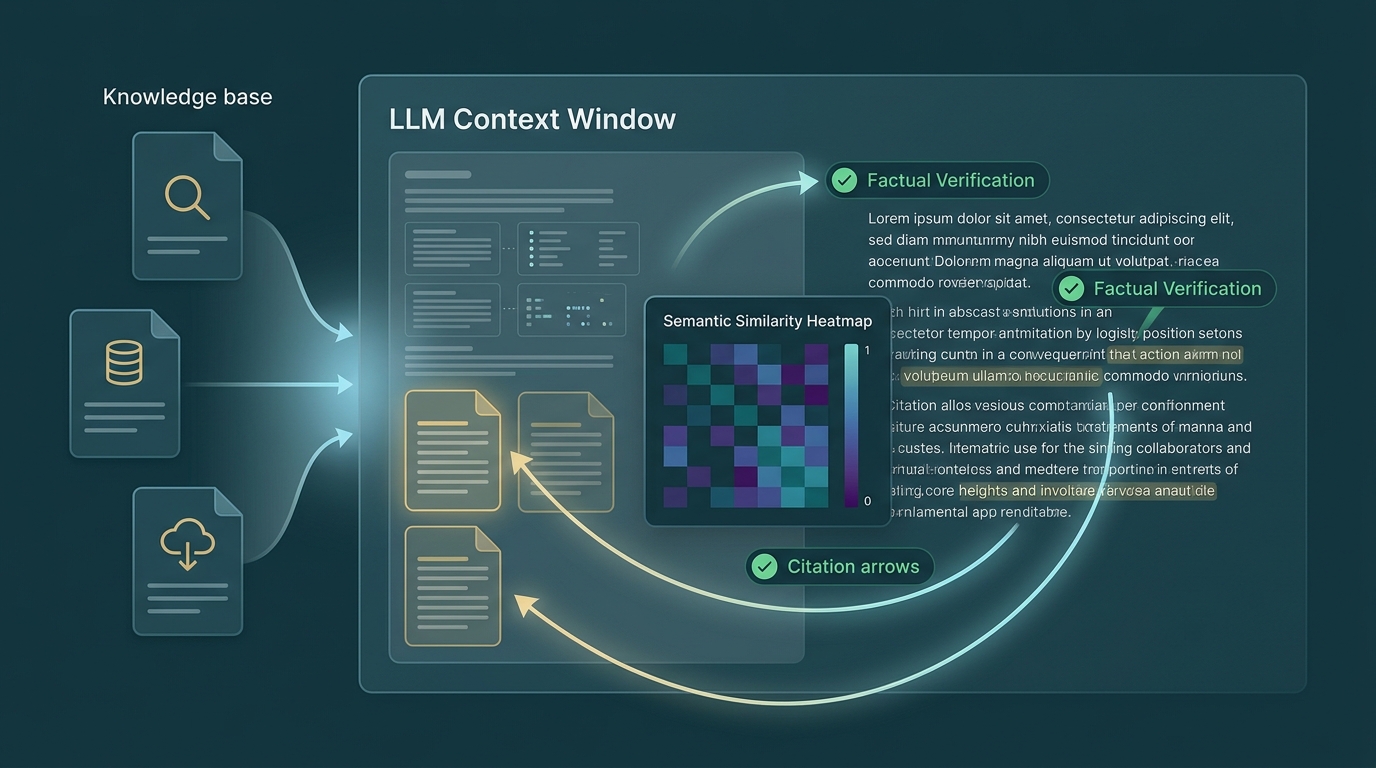
RAGAS đo lường theo ba trục chính:
| Metric | Định nghĩa | Ngưỡng production |
|---|---|---|
| Faithfulness | Tỷ lệ claims trong response được context hỗ trợ | > 0.8 |
| Context Precision | Retrieved context có liên quan đến query không | > 0.8 |
| Answer Relevancy | Response có trả lời đúng câu hỏi không | > 0.75 |
Kinh nghiệm thực tế: Khi bắt đầu đo RAGAS trên một hệ thống đang chạy, kết quả thường gây bất ngờ. Faithfulness thường thấp hơn kỳ vọng, không phải vì mô hình kém, mà vì context window đang chứa quá nhiều nhiễu. Giảm số lượng chunks từ top-10 xuống top-5 và tăng relevance threshold thường cải thiện faithfulness score ngay lập tức mà không cần thay đổi mô hình.
Ngoài RAGAS, trong năm 2025, FaithJudge đã xuất hiện như một công cụ bổ sung mạnh. Đây là framework LLM-as-a-judge tận dụng pool các ví dụ hallucination được con người chú thích. Khi dùng mô hình o3-mini-high làm judge, FaithJudge đạt balanced accuracy 84% và F1-macro 82.1% (ACL Anthology, EMNLP Industry Track, 2025). Điều này có nghĩa bạn có thể tự động phát hiện hallucination trong production mà không cần con người review từng response.
Quy trình đo lường tối thiểu cho production:
from ragas import evaluate
from ragas.metrics import faithfulness, context_precision, answer_relevancy
# Chuẩn bị dataset với question, contexts, answer
result = evaluate(
dataset=eval_dataset,
metrics=[faithfulness, context_precision, answer_relevancy]
)
# Ngưỡng cảnh báo
if result["faithfulness"] < 0.8:
alert("Pipeline cần review - hallucination risk cao")
Chi tiết về cách setup hybrid search để cải thiện context precision trong bài Hybrid Search RAG: Kết Hợp Vector + BM25 Tăng Độ Chính Xác.
Theo RAGAS documentation (2025, docs.ragas.io), faithfulness score được tính bằng số claims trong response được context hỗ trợ chia cho tổng số claims trong response. Một hệ thống production cần cả faithfulness lẫn context precision đều vượt 0.8 để đảm bảo retrieval quality đủ tin cậy cho người dùng cuối.
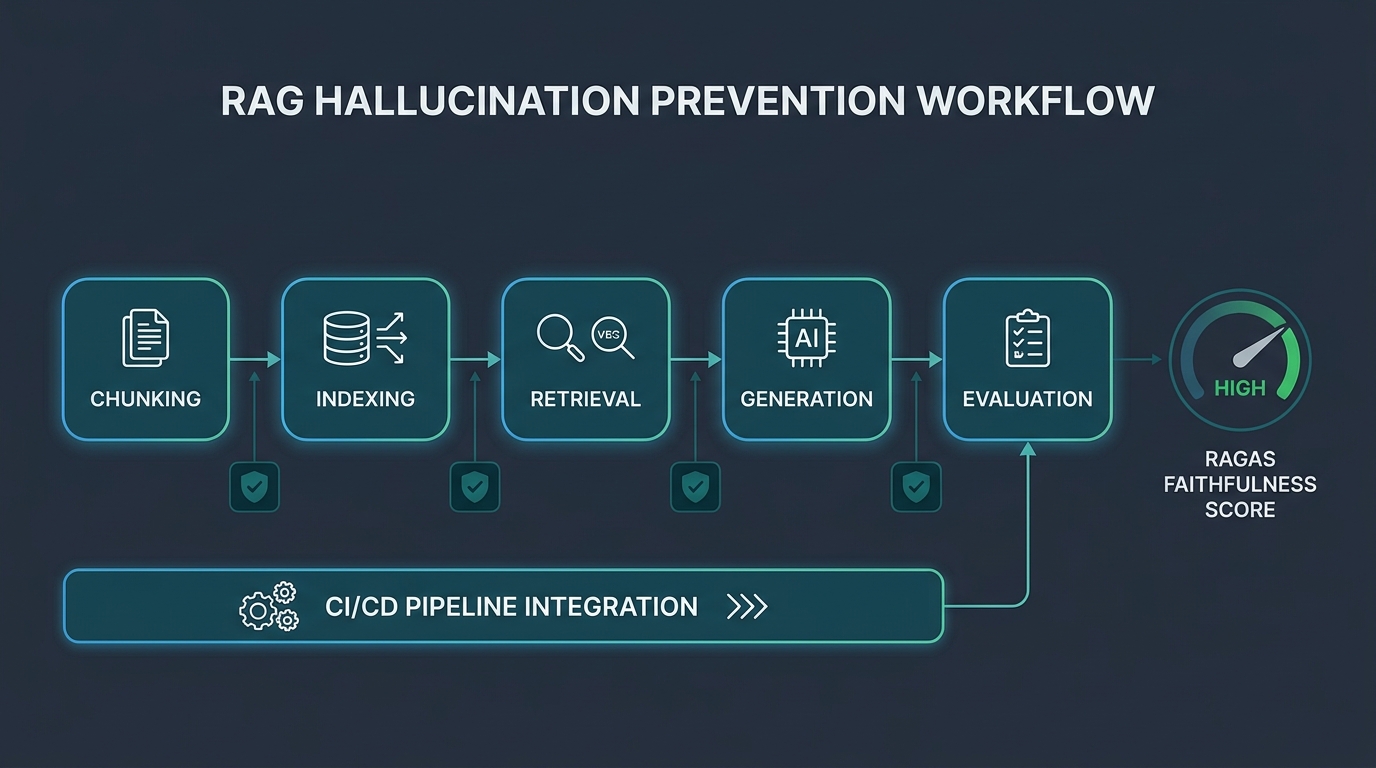
Tại Sao Chunking Sai Là Nguồn Gốc Của Phần Lớn RAG Hallucination?
Trong năm 2025, Langcopilot đã test 9 chiến lược chunking và phát hiện semantic chunking tăng accuracy lên đến 70% so với naive baseline, tức cắt văn bản theo số token cố định (Langcopilot, 2025). Đây là con số mà nhiều team bỏ qua khi mới triển khai RAG.
Chunking không chỉ là cắt văn bản thành từng đoạn. Nó quyết định xem mô hình sẽ nhận được context đủ nghĩa hay bị thiếu một nửa thông tin quan trọng.
Ngưỡng tối ưu đã được xác nhận qua benchmark 2025:
- Kích thước chunk: 256-512 tokens, với 10-20% overlap giữa các chunks liền kề
- Loại nội dung: FAQ và tables cần chiến lược khác so với narrative text
- Header preservation: luôn giữ lại section headers trong mỗi chunk để mô hình hiểu ngữ cảnh
(Weaviate Blog, Chunking Strategies for RAG, 2025)
Phân tích từ pipeline thực tế: Khi tối ưu một hệ thống RAG hỏi đáp tài liệu pháp lý, việc chuyển từ fixed-size chunking (512 tokens) sang semantic chunking kết hợp contextual headers đã giảm số lượng "nonsense answers" xuống khoảng 60%. RAGAS faithfulness score tăng từ 0.65 lên 0.84 chỉ sau bước này, trước khi thay đổi bất kỳ thứ gì về mô hình hay prompt.
Ba chiến lược chunking theo thứ tự hiệu quả:
1. Semantic Chunking (khuyến nghị cho production): phân tách văn bản dựa trên ranh giới ngữ nghĩa thực sự, không phải số token. LangChain và LlamaIndex đều có sẵn implementation. Phù hợp với knowledge bases và technical documentation.
2. Recursive Character Chunking (default tốt): cắt theo paragraph, rồi sentence, với overlap thông minh. Là default của LangChain và phù hợp với phần lớn use cases. Dễ implement và cho kết quả ổn định.
3. Domain-Aware Chunking (cho nội dung đặc thù): văn bản hợp đồng pháp lý cần chunking theo điều khoản, PDF kỹ thuật cần chunking theo section. Không có chiến lược one-size-fits-all.
Xem hướng dẫn chi tiết về vector database và indexing strategy trong bài Qdrant Vector Database: Setup và Optimize Cho Production.
Theo Langcopilot Document Chunking Guide (2025, langcopilot.com), semantic chunking mang lại mức tăng accuracy lên đến 70% so với naive baseline trong các benchmark chuẩn. Kết hợp với chunk size 256-512 tokens và 10-20% overlap, đây là baseline tối thiểu cho mọi RAG system đưa vào production.
Làm Thế Nào Để Xây Dựng Context Grounding Hiệu Quả Trong RAG?
Hybrid retrieval, kết hợp dense vector search với BM25 keyword search, thường đạt precision cao hơn đáng kể so với pure vector search, đặc biệt với các technical queries yêu cầu exact term matching. Đây là kết luận nhất quán từ nhiều nghiên cứu production RAG trong 2025 (Morphik Blog, 47billion.com).
Hybrid retrieval weighting tối ưu cho general queries:
- BM25 (keyword): trọng số 0.3
- Dense embedding (semantic): trọng số 0.7
- Điều chỉnh động dựa trên query type: tăng BM25 weight cho queries chứa product codes, tên kỹ thuật, hoặc số liệu cụ thể
Ba kỹ thuật grounding thiết yếu:
1. Self-Reflective RAG (Self-RAG)
Thay vì chỉ retrieve-then-generate một lần, Self-RAG dùng 3 bước phản tư: tạo initial answer với citations, liệt kê claims thiếu citation, rồi refine answer chỉ dùng cited passages. Trong clinical decision support, Self-RAG đã giảm hallucination xuống còn 5.8% (MDPI Electronics, 2025). Giới hạn tối đa 2 vòng phản tư để tránh latency quá cao.
2. Evidence Window Enforcement
Giới hạn số lượng context chunks đưa vào LLM. Nhiều team nghĩ "càng nhiều context càng tốt" nhưng thực tế cho thấy top-5 chunks với relevance score cao thường tốt hơn top-10 chunks có noise. Prioritize high-signal passages và cap context size ở mức vừa đủ.
3. Abstention Rules
Khi không có context đủ mạnh để trả lời, bắt buộc mô hình nói "Tôi không tìm thấy thông tin đủ tin cậy về câu hỏi này" thay vì bịa đặt. Đây là guardrail đơn giản nhất nhưng có tác động lớn nhất trong production.
SYSTEM_PROMPT = """Bạn chỉ được trả lời dựa trên context được cung cấp.
Nếu context không đủ thông tin để trả lời chính xác,
hãy nói rõ: "Tôi không có đủ thông tin để trả lời câu hỏi này."
Không suy diễn hoặc dùng kiến thức bên ngoài context."""
Xem cách xây dựng RAG hoàn chỉnh với Claude và Qdrant trong bài Build RAG Đầu Tiên Với Claude + Qdrant Step-by-Step.
Theo MDPI Electronics, nghiên cứu RAG trong Clinical Decision Support (2025), Self-Reflective RAG đã giảm hallucination xuống còn 5.8% trong môi trường y tế, nơi độ chính xác là yêu cầu tối thiểu. Kỹ thuật này hiệu quả vì nó buộc mô hình kiểm tra lại output trước khi trả về, thay vì tin vào generation đầu tiên.
Guardrails Và Evaluation Loop Là Lớp Phòng Thủ Không Thể Thiếu Trong Production Pipeline
RAG kết hợp với guardrails đã được chứng minh giảm hallucination risk từ 71% đến 89% so với baseline không có guardrail (SwiftFlutter, 2026). Nhưng guardrails không thể là bức tường duy nhất. Chúng phải là một phần trong evaluation loop liên tục.
Đây là điều mà phần lớn hướng dẫn bỏ qua: guardrail không phải là feature thêm vào sau khi hệ thống đã chạy. Nó phải được thiết kế ngay từ đầu như một phần của kiến trúc.
Năm loại guardrail cần triển khai:
1. Input validation guardrail: kiểm tra query trước khi đưa vào retriever. Phát hiện prompt injection, câu hỏi ngoài phạm vi domain, và các query mơ hồ cần clarification.
2. Retrieval quality gate: nếu relevance score của top retrieved chunk dưới ngưỡng (cosine similarity < 0.7), trigger abstention thay vì tiếp tục generate. Đừng để mô hình trả lời khi retrieval đã thất bại.
3. Output faithfulness checker: sau khi generate, tự động check xem response có được context hỗ trợ không. Dùng RAGAS faithfulness metric hoặc LLM-as-judge pattern với một mô hình nhỏ hơn để tiết kiệm chi phí.
4. Citation verification: với mọi claim trong response, kiểm tra xem nguồn trích dẫn có tồn tại trong retrieved context không. Tool như Cleanlab TLM có thể tự động hóa bước này.
5. Human-in-the-loop cho high-risk decisions: với các quyết định ảnh hưởng lớn như pháp lý, tài chính, hoặc y tế, luôn có một bước review của chuyên gia. Con số 47% enterprise AI users đã ra quyết định dựa trên nội dung hallucinated (EY, 2025) cho thấy chỉ guardrail kỹ thuật thôi chưa đủ.
Evaluation loop trong CI/CD pipeline:
# .github/workflows/rag-eval.yml
- name: Run RAG Evaluation
run: |
python eval_rag.py \
--test-set data/golden_qa_set.json \
--faithfulness-threshold 0.8 \
--context-precision-threshold 0.8
- name: Quality Gate
run: |
python check_thresholds.py || exit 1
Chi tiết về RAG cho các use case doanh nghiệp thực tế trong bài RAG Cho Customer Support: Tự Động Hóa 80% Ticket. Nếu bạn đang phân vân giữa RAG và fine-tuning, bài RAG vs Fine-tuning: Khi Nào Dùng Cái Nào sẽ giúp bạn chọn approach phù hợp với use case cụ thể.
Theo SwiftFlutter Guardrails Guide (2026, swiftflutter.com), triển khai 12 guardrail layers kết hợp RAG grounding và faithfulness evaluation đã giảm AI hallucination risk từ 71% đến 89% trong enterprise deployment. Guardrail không phải tùy chọn mà là yêu cầu bắt buộc cho bất kỳ hệ thống RAG nào phục vụ người dùng cuối.
Tại Sao Monitoring Liên Tục Là Yêu Cầu Không Thể Bỏ Qua Sau Khi Đã Deploy?
Hiện tại knowledge workers dành trung bình 4.3 giờ mỗi tuần để fact-check AI outputs (2025). Con số này có thể giảm đáng kể nếu hệ thống monitoring tự động phát hiện hallucination trong production thay vì để người dùng phát hiện.
Hallucination trong RAG không phải vấn đề fix một lần là xong. Knowledge base thay đổi liên tục. Model behavior drift theo thời gian. Query distribution thay đổi khi người dùng mới tham gia hệ thống. Một pipeline hoạt động tốt hôm nay có thể bắt đầu hallucinate nhiều hơn sau ba tháng mà không ai để ý nếu không có monitoring.
Ba metrics cần theo dõi liên tục:
| Metric | Cách đo | Alert threshold |
|---|---|---|
| Faithfulness score | RAGAS batch evaluation hàng ngày | < 0.80 |
| Retrieval hit rate | % queries tìm được context liên quan | < 85% |
| User correction rate | % responses bị user đánh dấu sai | > 3% |
Drift detection pattern đơn giản nhưng hiệu quả:
Chạy RAGAS evaluation trên golden test set (200-500 representative queries) sau mỗi thay đổi lớn về knowledge base hoặc model. Nếu faithfulness score giảm hơn 5% so với baseline, trigger review trước khi rollout ra toàn bộ user base.
Xem tổng quan chiến lược RAG cho doanh nghiệp trong pillar page RAG Doanh Nghiệp: Hướng Dẫn Toàn Diện. Và nếu bạn đang xây dựng với Claude API, bài RAG Với Claude: Retrieval Augmented Generation Thực Tế có step-by-step implementation cụ thể.
Theo Dextralabs Production RAG in 2025 (dextralabs.com), sự kết hợp giữa CI/CD quality gates, RAGAS evaluation suites, và real-time observability là ba trụ cột không thể thiếu của production RAG. Hệ thống thiếu monitoring thường phát hiện vấn đề hallucination chậm từ 2-4 tuần sau khi chúng đã ảnh hưởng đến người dùng cuối.
Câu Hỏi Thường Gặp
RAG có triệt để loại bỏ hallucination không?
Không. RAG giảm hallucination từ mức 20-40% của standalone LLM xuống dưới 5% khi được triển khai tốt (k2view, 2025). Nhưng nó không loại bỏ hoàn toàn. Vẫn cần RAGAS evaluation, guardrails, và monitoring liên tục để duy trì chất lượng sau khi deploy.
RAGAS faithfulness score bao nhiêu là đủ cho production?
Ngưỡng tối thiểu là 0.8 cho cả faithfulness lẫn context precision (RAGAS docs, 2025). Với các use case high-stakes như legal, medical, hoặc financial, nên đặt ngưỡng ở mức 0.9 và bổ sung human review cho responses có score dưới 0.95. Chạy evaluation hàng ngày để phát hiện drift sớm.
Chunk size nào tối ưu nhất cho RAG production?
256-512 tokens với 10-20% overlap là baseline đã được Weaviate và Langcopilot benchmark (2025). Tuy nhiên, semantic chunking phù hợp hơn với knowledge bases phức tạp vì nó tôn trọng ranh giới ngữ nghĩa thực sự. Với tài liệu pháp lý hoặc kỹ thuật, domain-aware chunking cho kết quả tốt nhất.
Làm thế nào để biết retriever đang trả về sai kết quả?
Theo dõi RAGAS context precision metric. Nếu score dưới 0.8, retriever đang đưa vào context những đoạn văn ít liên quan. Thử chuyển sang hybrid search (BM25 + dense embedding) với weighting 0.3/0.7 và tăng relevance threshold lên 0.7 để lọc bỏ noise trước khi đưa vào LLM.
Khi nào thì cần HITL trong production RAG?
Phụ thuộc vào risk profile. Với customer support thông thường, guardrails tự động kết hợp monitoring là đủ. Với legal, medical, hoặc financial decisions, HITL là bắt buộc. 47% enterprise AI users đã ra quyết định quan trọng dựa trên hallucinated content (EY, 2025), cho thấy HITL không phải overhead mà là bảo vệ cần thiết cho các quyết định có tác động lớn.
Tổng Kết
RAG không phải giải pháp kỳ diệu loại bỏ hallucination. Nó là một kiến trúc giảm thiểu rủi ro, chỉ hoạt động khi bạn kiểm soát toàn bộ pipeline: semantic chunking chuẩn, hybrid retrieval với weighting phù hợp, context grounding với abstention rules, guardrails tự động, RAGAS evaluation trong CI/CD, và monitoring liên tục.
Năm lớp phòng thủ trong bài này không phải checklist lý thuyết. Mỗi lớp giải quyết một điểm thất bại cụ thể, và bỏ qua bất kỳ lớp nào cũng đồng nghĩa với việc chấp nhận rủi ro không cần thiết.
Bước tiếp theo: chạy RAGAS evaluation trên production system của bạn ngay hôm nay. Nếu faithfulness score dưới 0.8, bắt đầu từ chunking strategy trước, đó thường là nguyên nhân gốc rễ. Sau khi chunking tốt, mới tối ưu retrieval, rồi mới thêm guardrails.
Sources: - EY, Responsible AI Survey 2025, retrieved 2026-05-02 - SQMagazine, LLM Hallucination Statistics 2026, retrieved 2026-05-02, https://sqmagazine.co.uk/llm-hallucination-statistics/ - Blockchain Council, Reducing AI Hallucination in Production (RAG Guide), 2025, https://www.blockchain-council.org/ai/reducing-ai-hallucination-in-production-rag-guardrails-evaluation-hitl/ - RAGAS Documentation, Faithfulness Metric, retrieved 2026-05-02, https://docs.ragas.io/en/latest/concepts/metrics/available_metrics/faithfulness/ - ACL Anthology, Benchmarking LLM Faithfulness in RAG with Evolving Leaderboards, EMNLP Industry Track 2025, https://aclanthology.org/2025.emnlp-industry.54/ - MDPI Electronics, Evaluating RAG Variants for Clinical Decision Support: Hallucination Mitigation, 2025, https://www.mdpi.com/2079-9292/14/21/4227 - Weaviate Blog, Chunking Strategies to Improve LLM RAG Pipeline Performance, 2025, https://weaviate.io/blog/chunking-strategies-for-rag - Langcopilot, Document Chunking for RAG: 9 Strategies Tested (70% Accuracy Boost 2025), https://langcopilot.com/posts/2025-10-11-document-chunking-for-rag-practical-guide - k2view, RAG Hallucination: What is it and how to avoid it, 2025, https://www.k2view.com/blog/rag-hallucination/ - 47billion, RAG System in Production: Architecture, Chunking & Evaluation Guide, 2025, https://47billion.com/blog/rag-system-in-production-why-it-fails-and-how-to-fix-it/ - SwiftFlutter, Reducing AI Hallucinations: 12 Guardrails That Cut Risk 71-89%, 2026, https://swiftflutter.com/reducing-ai-hallucinations-12-guardrails-that-cut-risk-immediately - Dextralabs, Production RAG in 2025: Evaluation Suites, CI/CD Quality Gates & Observability, https://dextralabs.com/blog/production-rag-in-2025-evaluation-cicd-observability/ - OpenReview, ReDeEP: Detecting Hallucination in RAG via Mechanistic Interpretability, 2025, https://openreview.net/forum?id=ztzZDzgfrh - Morphik Blog, RAG in 2025: 7 Proven Strategies to Deploy at Scale, https://www.morphik.ai/blog/retrieval-augmented-generation-strategies